
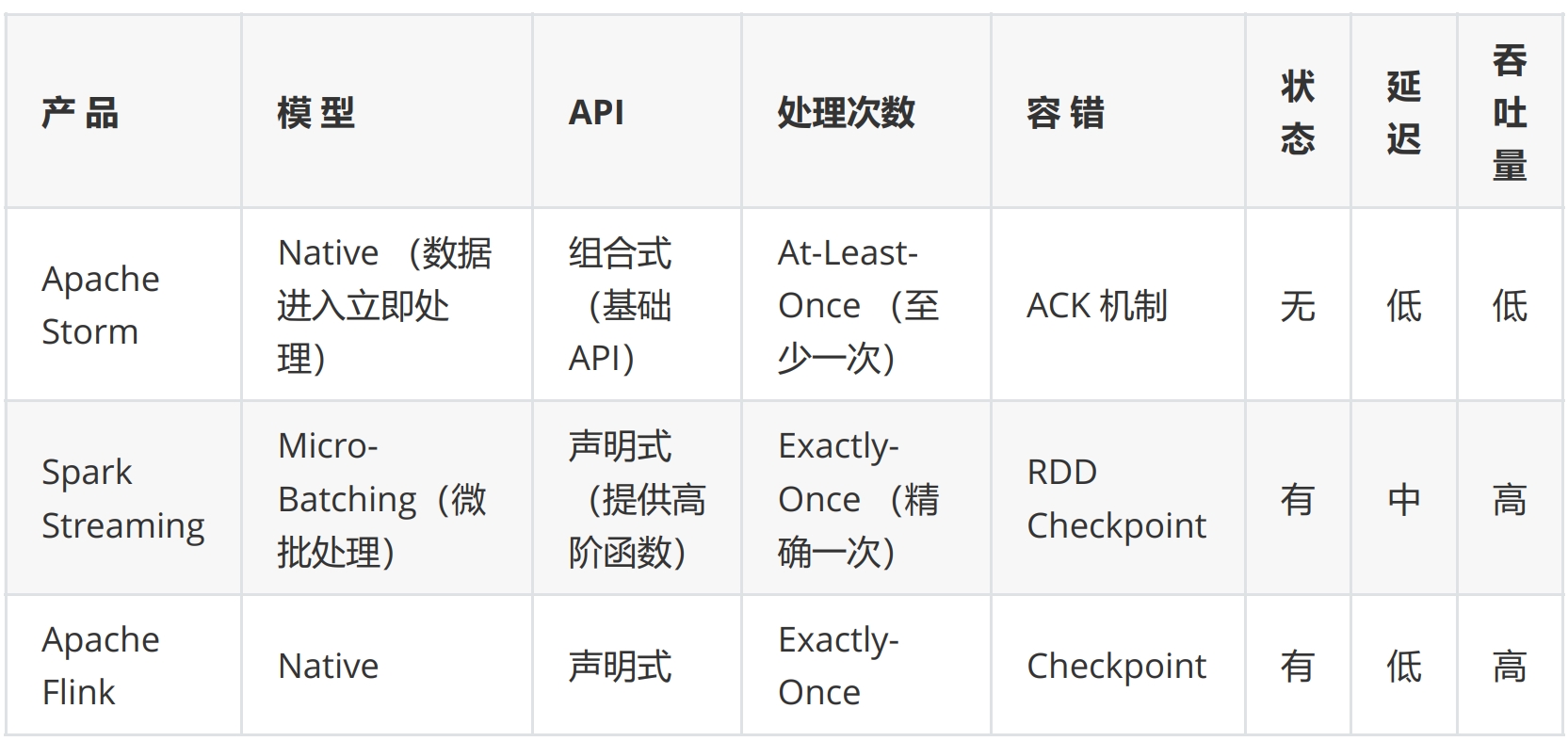
当前大数据领域主流的流式计算框架有 Apache Storm、Spark Streaming、Apache Flink 三种。通常将 Apache Storm 称为第一代流式计算框架,Spark Streaming 称为……
当前大数据领域主流的流式计算框架有 Apache Storm、Spark Streaming、Apache Flink 三种。通常将 Apache Storm 称为第一代流式计算框架,Spark Streaming 称为第二代流式计算框架,第三代实时计算框架就是今天的主角 Apache Flink,这三种计算框架的区别如下表所示。
一、模型
1.1 Micro-Batching
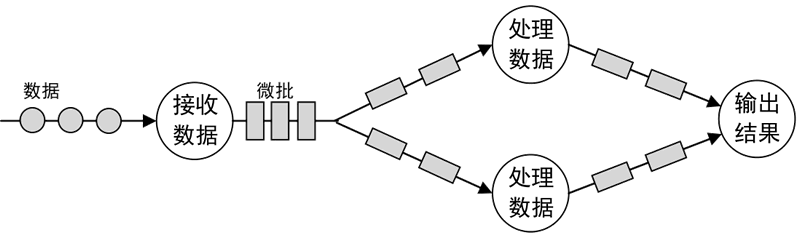
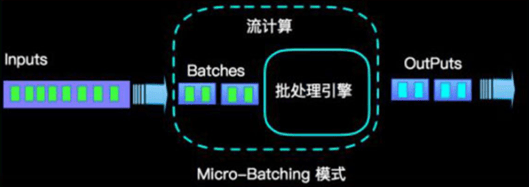
Micro-Batching:微批流处理。把输入的数据按照预先定义的时间间隔(例如1秒钟)分成短小的批量数据,流经流处理系统进行处理,如下图所示。
1.2 Native
Native:原生流处理。指输入的数据一旦到达,就立即进行处理,一次处理一条数据,如下图所示。
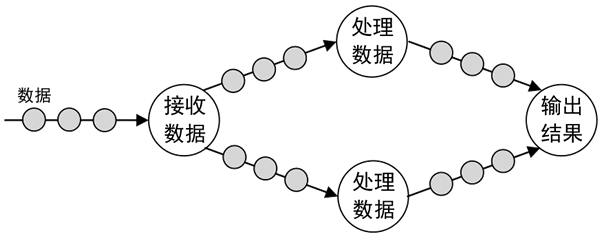

Storm 和 Flink 使用的是原生流处理,一次处理一条数据,是真正意义的流处理;而 SparkStreaming 实际上是通过批处理的方式模拟流处理,一次处理一批数据(小批量)。
2. API
Storm 只提供了组合式的基础 API,而 Spark Streaming 和 Flink 都提供了封装后的高阶函数,例如 map()、filter(),以及一些窗口函数、聚合函数等,使用这些函数可以轻松处理复杂的数据,构建并行应用程序。
3. 数据处理次数
在流处理系统中,对数据的处理有 3 种级别的语义:At-Most-Once(最多一次)、At-LeastOnce(至少一次)、Exactly-Once(精确一次):
- At-Most-Once:最多一次,数据可能会丢失,但是不会产生数据被重复消费的情况,该层语义的可靠性最低。
- At-Least-Once:至少一次,数据肯定不会丢失,但是可能会导致数据被重复的处理。
- Exactly-Once:精确一次,对于一些非常重要的信息,数据不仅不会丢失,也不会被重复的处
理。
由此可见,衡量一个流处理系统能力的关键是 Exactly-Once。
Storm 实现了 At-Least-Once,可以对数据至少处理一次,但不能保证仅处理一次,这样就会导致数据重复处理的问题,因此针对计数类的需求可能会产生一些误差;Spark Streaming 和 Flink 都实现了 Exactly-Once,可以保证对数据仅处理一次,即每个记录将被精确处理一次,数据不会丢失,并且不会重复处理。
4. 容错
由于流处理系统的许多作业都是 7×24 小时运行的,不断有输入的数据,因此容错性比批处理系统更难实现。一旦因为网络等原因导致节点宕机,流处理系统应该具备从这种失败中快速恢复的能力,并从上一个成功的状态重新处理。
Storm 通过使用 ACK(确认回执,即数据接收方接收到数据后要向发送方发送 Storm 通过使用ACK(确认回执,即数据接收方接收到数据后要向发送方发送确认回执,以此来保证数据不丢失)机制来确认每一条数据是否被成功处理,当处理失败时,则重新发送数据。这样很容易做到保证所有数据均被处理,没有遗漏,但这种方式不能保证数据仅被处理一次,因此存在同一条数据重复处理的情况。
由于 Spark Streaming 是微批处理,不是真正意义上的流处理,其容错机制的实现相对简单。Spark Streaming 中的每一批数据成为一个 RDD(Resilient Distributed Dataset,分布式数据集)。RDD Checkpoint(检查点)机制相当于对 RDD 数据进行快照,可以将经常使用的 RDD 快照到指定的文件系统中,例如 HDFS。当机器发生故障导致内存或磁盘中的 RDD 数据丢失时,可以快速从快照中对指定的 RDD 进行恢复。
Flink 的容错机制是基于分布式快照实现的,通过 CheckPoint 机制保存流处理作业某些时刻的状态,当任务异常结束时,默认从最近一次保存的完整快照处恢复任务。
5. 状态
流处理系统的状态管理是非常重要的,Storm 没有实现状态管理,Spark Streaming 和 Flink 都实现了状态管理。通过状态管理可以把程序运行中某一时刻的数据结果保存起来,以便于后续的计算和故障的恢复。
日常生活中,所有数据都是作为连续的事件流创建的。比如网站或者移动应用中的用户交互动作,订单的提交,服务器日志或传感器测量数据:所有这些都是事件流。实际上,很少有应用场景,能一次性地生成所需要的完整(有限)数据集。实际应用中更多的是无限事件流。有状态的流处理就是用于处理这种无限事件流的应用程序设计模式,在公司的 IT 基础设施中有广泛的应用场景。
如果想要处理无限事件流,并且不愿意繁琐地每收到一个事件就记录一次,那这样的应用程序就需要是有状态的,也就是说能够存储和访问中间数据。当应用程序收到一个新事件时,它可以从状态中读取数据,或者向该状态写入数据,总之可以执行任何计算。原则上讲,我们可以在各种不同的地方存储和访问状态,包括程序变量(内存)、本地文件,还有嵌入式或外部数据库。
Apache Flink 将应用程序状态,存储在内存或者嵌入式数据库中。由于 Flink 是一个分布式系统,因此需要保护本地状态以防止在应用程序或计算机故障时数据丢失。Flink 通过定期将应用程序状态的一致性检查点(Checkpoint)写入远程且持久的存储,来保证这一点。如下图显示了有状态的流式Flink 应用程序。

6. 延迟
由于 Storm 和 Flink 是接收到一条数据就立即处理,因此数据处理的延迟很低;而 SparkStreaming 是微批处理,需要形成一小批数据才会处理,数据处理的延迟相对偏高。
7. 吞吐量
Storm 的吞吐量相对来说较低,Spark Streaming 和 Flink 的吞吐量则比较高。较高的吞吐量可以提高资源利用率,减小系统开销。
总的来说,Storm 非常适合任务量小且延迟要求低的应用,但要注意 Storm 的容错恢复和状态管理都会降低整体的性能水平。如果你要使用 Lambda 架构,并且要集成 Spark 的各种库,那么 Spark Streaming 是一个不错的选择,但是要注意微批处理的局限性以及延迟问题。Flink 可以满足绝大多数流处理场景,提供了丰富的高阶函数,并且也针对批处理场景提供了相应的 API,是非常有前景的一个项目。
 微信扫一扫
微信扫一扫 















还没有评论呢,快来抢沙发~